
Alissa Knight
We taught our offensive-security agent to do more than fix his mistakes. Now he fixes the part of itself that makes them.
A quick naming note before we start, because two names show up throughout this post and they are not interchangeable. Reaper is the autonomous offensive-security agent: the thing that runs operations, probes a target, and emits findings. Predator is the harness and AI model that powers him; the orchestration layer that drives every operation and the reasoning engine underneath it. Reaper is the operator you see in the report. Predator is the machinery doing the work. This post is about Predator, specifically a new capability we built into the harness layer, so most of what follows describes Predator’s internals, with Reaper as the agent that machinery drives.
Reaper already knew how to self-heal. At the end of every operation, Predator reviewed his findings, stripped out the false positives, and wrote a lesson so the same mistake would never ship again. That is a real capability, and it works. But the harness had a ceiling: the healing pass itself was fixed. Same routing, same judge calibration, same retrieval weights, every single time. If a finding landed in a strategy bucket that couldn’t resolve it, it sat there flagged NEEDS_REVIEW forever, and no amount of re-running changed that.
In Predator’s latest release we removed the ceiling. Predator now performs recursive self-healing (RSI): after each healing pass, the harness also improves the machinery that did the healing, so the next pass starts better-calibrated than the last, the improvements compound across cycles, and the loop is mathematically guaranteed to either converge, hit a depth bound, or detect that it is spinning its wheels. The healing process became a first-class object the system can inspect and rewrite.
This post walks through what we built, exactly how he works end-to-end, and the test-derived empirical data behind every claim. The numbers in the charts marked Measured come straight out of the test suite on main; the one chart marked Schematic illustrates a mechanism rather than reporting an aggregate statistic, and is labeled as such.

01The false-positive trust problem
An autonomous offensive-security agent that emits findings is only ever as trustworthy as his false-positive rate. A scanner that cries BOLA on every own-record read poisons the report and burns the one resource a security team can never get back: analyst attention. The fastest way to make a powerful agent useless is to make a human double-check everything he says.
Predator’s original self-heal subsystem solved the object-level version of this problem. Review the findings of a completed operation, suppress the false positives, draft a learned exemplar so that exact pattern is killed on every future run before it ever reaches a report. That part shipped, and he is genuinely good. But he was a single, fixed pass. The routing that decided how to verify a finding, the calibration of the LLM judge, the retrieval weights that surfaced the right past lesson — all of them were frozen constants. When a finding type had no safe way to be re-verified (think a state-mutating vulnerability you can’t simply replay), the system had no move. He flagged the finding for a human and moved on. Same outcome, every time, forever.
RSI closes that loop. The healing process itself becomes the thing being healed.
The interesting design question is not “how do we remove false positives” — we already could. It is: what if the agent could notice that his verification strategy was the bottleneck, and rewrite that strategy, mid-operation, for the next cycle? That is the entire idea behind recursive self-healing.
02From self-healing to recursive self-healing
The cleanest way to understand the leap is to separate the two levels at which Predator now learns. The object level reasons about findings: is this real, or a false positive? The meta level reasons about the reasoning: is the way we’re judging findings actually working, and how should we change it for the next cycle?
Classical self-healing only ever operated at the object level. RSI adds the meta level and wires it into a loop. After a heal pass completes, a stateless component called the MetaLearner inspects the cycle that just happened — what got resolved, what didn’t, how confident the verdicts were, which retrieval signals fired — and proposes concrete changes to the healing machinery. Those changes are applied, and the next cycle runs on findings that are still uncertain, but now with better machinery. Crucially, skills drafted in cycle N are visible to cycle N+1. That is the compounding effect: each cycle inherits everything every previous cycle learned.
Each recursive cycle runs under a derived operation identifier — <op>:rsi:<depth> — so its corpus entries and drafted skills stay cleanly separated from the original cycle’s, while the shared skill store accumulates every learned lesson across the entire recursion chain. The original operation’s audit trail is never muddied; the recursion is fully traceable.
03The RSI loop
At its heart RSI is a seven-step loop. It runs a full object-level heal pass, measures the result, isolates what’s still uncertain, asks the meta level how to do better, applies those improvements so they accumulate, and re-runs on just the uncertain remainder — until a termination condition fires.
The diagram below shows how the two levels nest. The inner ring is the object-level funnel doing its familiar job. The outer ring is the meta level, observing each completed cycle and feeding rewrites back into the machinery that drives the next one.
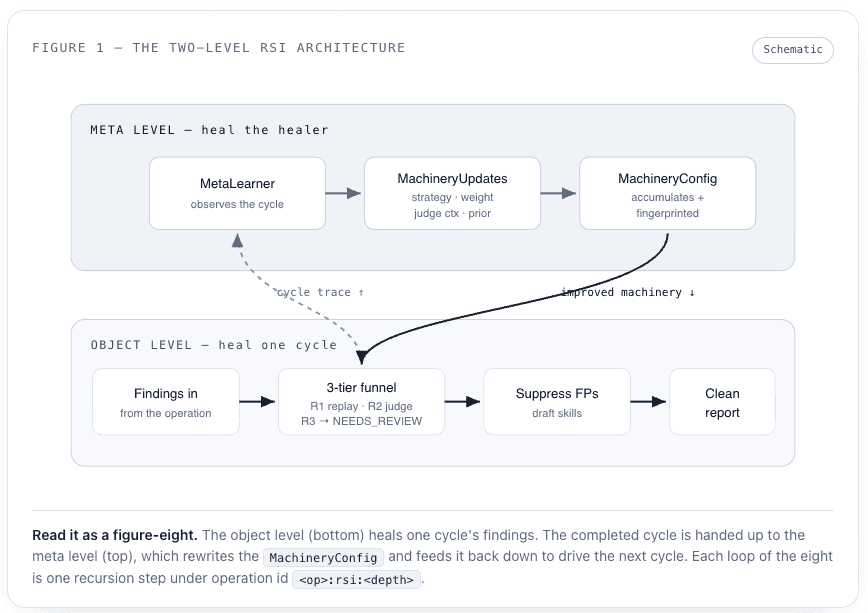
04Four termination guarantees
The first question any reviewer asks about a recursive system is: what stops it? Unbounded self-modification is exactly the kind of thing that sounds clever in a demo and pages you at 3 a.m. in production. RSI has four termination conditions, checked in order, every cycle.
Condition | Meaning |
|---|---|
| No uncertain findings remain — the report is clean and the loop exits successfully. |
|
|
| The machinery fingerprint repeated — the system is churning, not advancing. Exit immediately. |
| The MetaLearner produced zero proposals — there is nothing left to tune. |
The chart below depicts the three behaviors the RSI test matrix pins down, traced over recursive cycles on a representative operation. A finding that the old single-pass healer would have left flagged forever (the faint dashed line) is, under RSI, either resolved into convergence once the verification strategy is rerouted, or — if it genuinely cannot be resolved — escalated cleanly to a human at the depth bound. No path runs away.
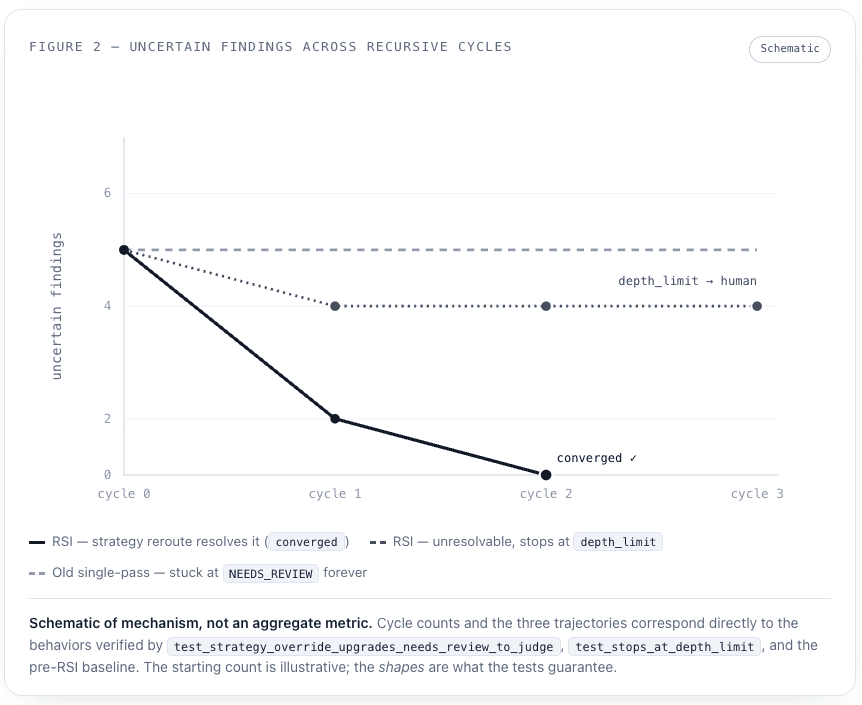
05The machinery it rewrites
The object the meta level edits is MachineryConfig (machinery.py:31). It is worth being precise about what this is: it is not what the system knows (that’s the skill store and the corpus) — it is how the system reasons. It is the runtime-tunable state of the healer itself, and it accumulates four kinds of MachineryUpdate as the recursion deepens.
Update kind | What it changes |
|---|---|
| Reroute a finding type to a different replay strategy on the next cycle — e.g. push a no-replay finding into the LLM judge instead. |
| Nudge a retrieval-weight multiplier, hard-clamped to |
| Inject a calibration line into the LLM judge’s prompt on subsequent cycles. |
| Shift the Bayesian gauge prior toward observed data so the next cycle’s precision estimate starts more accurate. |
Every update is appended to an audit log (applied_updates), so you can always reconstruct exactly how the healer’s behavior drifted over a recursion chain. And the config exposes a stable 16-character hex fingerprint() (machinery.py:98). That fingerprint is the linchpin of loop detection: if the same fingerprint appears twice in a recursion chain, the machinery isn’t advancing, and the loop terminates with loop_detected. You cannot churn forever, because churning is observable.
Why a fingerprint and not a counter? A depth limit alone would let the system waste its entire budget re-applying an identical, useless change three times before quitting. The fingerprint catches non-advancement on the very next cycle — the difference between “we tried three times” and “we noticed after one that we were repeating ourselves.”
06The object-level funnel (unchanged — RSI drives it)
RSI does not replace the false-positive funnel; it steers it. The funnel (funnel.py) is a three-tier verdict pipeline, and it is deliberately the same code whether or not the recursion engine is active.
Tier | Method | Used for | Confidence |
|---|---|---|---|
R1 | Deterministic replay (primary) | SQLi, XSS, cmdi, auth-bypass — re-issue the request, check the indicator. | 0.8 – 0.9 |
R2 | LLM-judge equivalence (secondary) | The only place a model is involved. Injected | model-scored |
R3 | No replay | State-mutating / rate-bound: | — |
The single most important detail in the entire subsystem: skill injection happens before any replay (funnel.py:163). If an active learned exemplar matches the finding’s identity, the finding is suppressed immediately with confidence=1.0, source="skill" — before R1, R2, or R3 is ever consulted. That is what prevents recurrence on a re-run. The false positive is killed before the judge is even asked. The judge’s job is to learn the lesson once; the skill’s job is to enforce it for free, forever.
When the RSI engine is active, two things change in how the funnel is wired — not in the funnel itself. The FindingVerifier is constructed with the shared MachineryConfig, so RSI-learned strategy overrides take effect through resolve_strategy_with_config (funnel.py:42). And the judge is wrapped in an AugmentedJudge (funnel.py:79) that forwards the accumulated calibration context from prior cycles into the live model prompt. The funnel code is identical; what flows through it gets smarter each cycle.
07The MetaLearner — healing the healer
The MetaLearner (meta_learner.py) is intentionally stateless. It observes exactly one completed heal cycle and returns a list of MachineryUpdate proposals. Statelessness is a feature: all the memory lives in the fingerprinted MachineryConfig, which means the learner is trivially testable and can’t accumulate hidden, un-auditable state of its own. Four rules run every cycle.
1 · Strategy upgrades. NEEDS_REVIEW verdicts that came from R3 (no safe replay) get rerouted through R2 (the LLM judge) on the next cycle, where the judge can classify them without a live replay. This is the core RSI behavior — it is precisely how a finding that was “stuck forever” under the old healer becomes resolvable.
2 · Judge calibration. Low-confidence verdicts (below 0.70) trigger an injected calibration context line — literally “Prior cycle had N low-confidence verdict(s)… Apply extra scrutiny” — so the model is told, in its own prompt, where it was shaky last time.
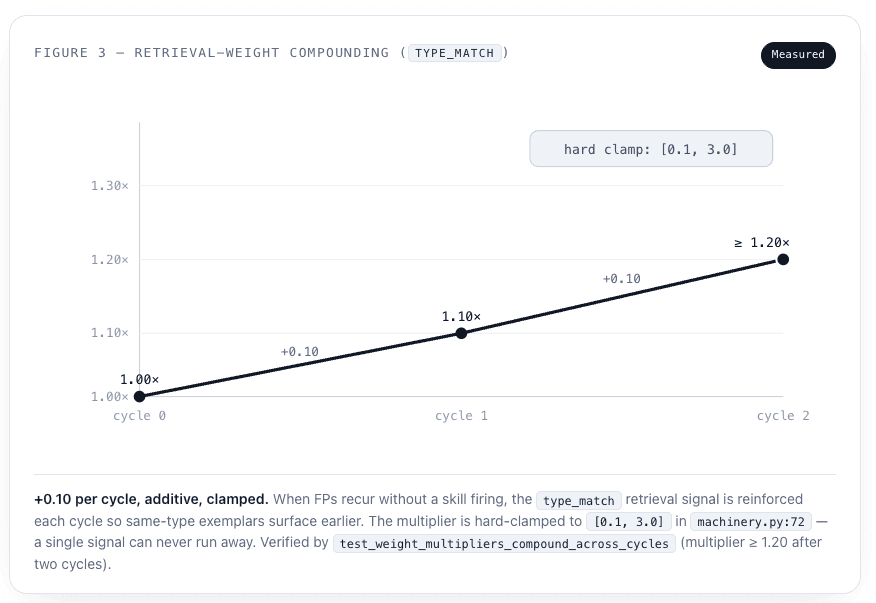
3 · Weight adjustment. The learner reinforces whichever retrieval signal drove a correct suppression. If human-approved skills fired, it boosts the human_verdict weight by +0.10. If false positives exist but no skill fired, it boosts type_match by +0.10 to surface same-type exemplars earlier next time.
4 · Prior calibration. If the gauge is still calibrating and precision is below 0.80, it tightens the Beta prior toward observed data, so the next cycle’s gauge starts from a more honest place.
Object-level healing judges findings. Meta-level healing judges the judging.
Rule 3 is where the “compounding” in recursive self-healing becomes concrete and measurable. Because each weight_delta is additive and the deltas accumulate in the config, a retrieval signal that keeps proving useful keeps getting reinforced — cycle after cycle — until it is either doing its job or hits the hard clamp at 3.0. The chart below traces the type_match multiplier across two cycles where false positives appeared but no skill had yet fired, exactly the case test_weight_multipliers_compound_across_cycles verifies.
08The accuracy gauge — and why it moves against the agent
You cannot manage what you cannot measure, and a self-improving system needs an honest scorecard or he will happily improve himself into delusion. Predator’s gauge (gauge.py) is a 30-day, Bayesian-smoothed, human-verified precision score. Human labels are authoritative — a human verdict is the effective verdict, full stop. The posterior is Beta(tp + α, fp + β) with a cold-start prior of Beta(9, 1): the fleet starts out assuming 90% precision and has to earn its way to the truth from there. The gauge recomputes after every learning event — a human label, or a skill firing — and reports a 95% credible interval, a trend delta versus the previous cycle, the impact of skills that fired, and human coverage. It stays flagged calibrating until there’s enough human-verified signal to trust the headline.
The chart below is the single most important empirical artifact in this whole writeup, because it shows the gauge doing the thing you most want and least expect from a system grading his own homework: getting less sure of himself when a human says he was wrong. These are the exact posterior distributions from the gauge test, with the means computed directly from the Beta parameters.
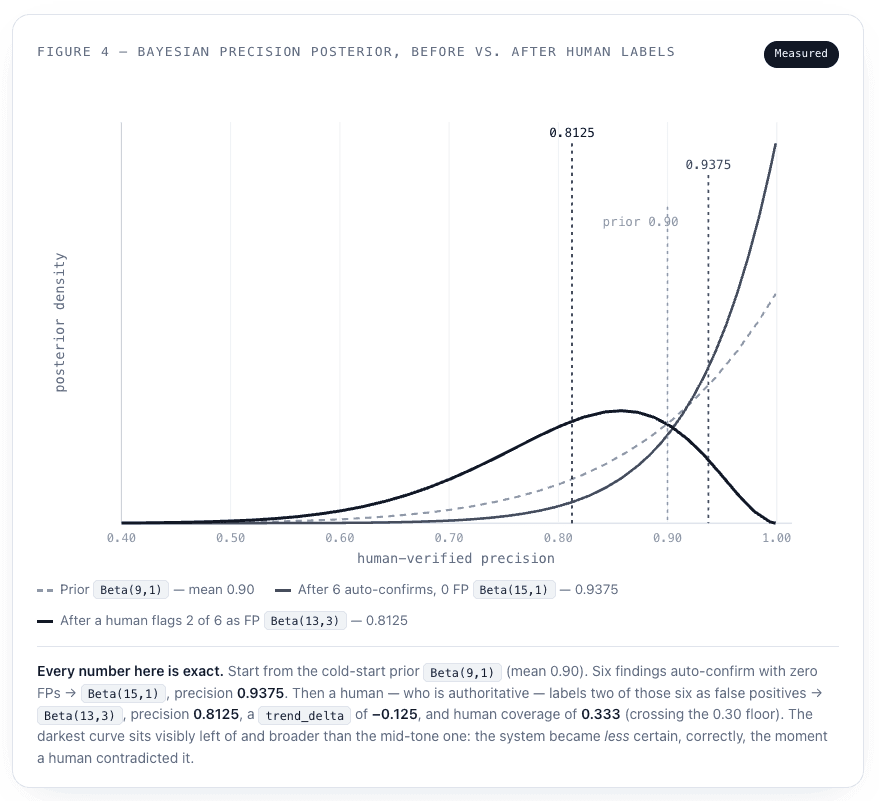
This is the property that makes the recursion safe to trust. A self-improving loop that could only ever revise its confidence upward would be a machine for manufacturing false comfort. Predator’s gauge moves in whichever direction the human-verified evidence points — and when that direction is “you were wrong,” the gauge says so, loudly, in the next cycle’s prior.
09What the tests actually prove
None of the above is a whiteboard sketch. Every guarantee in this post is pinned by a test on main, run 2026-06-18. The headline numbers:

The RSI test matrix (tests/test_recursive_selfheal.py, 441 lines) is organized so each test pins exactly one termination or compounding guarantee. This is the part that matters: the recursion’s safety properties aren’t argued, they’re asserted.
Test | Behavior verified |
|---|---|
| First cycle resolves everything → |
|
|
| Null MetaLearner → |
| The core RSI behavior. |
| Two FP-no-skill cycles → |
| Idempotent MetaLearner re-proposing the same override → |
| FPs found in different cycles are all absent from the final merged report. |
| Each |
7 × | Fingerprint changes on every update kind, is idempotent on re-apply, weights reflect multipliers, multiplier clamps at 3.0. |
The live end-to-end run deserves a callout: against the real AssailBank lab target, Predator ran read-only recon and detection through his scoped client, the answer-key judge confirmed a genuine finding, a controlled false positive was learned into a SKILL.md package with evidence, the report was filtered, and a later operation loaded that skill from the queue and suppressed the same mistake by source="skill" — before the judge ever ran. The whole loop, end to end, against a live target, in two and a half minutes.
10The backlog cleans the future
RSI runs at the end of an operation, which is perfect for new work. But every tenant arrives with a backlog of completed reports — findings that were never run through the funnel, never turned into suppression skills, never scored against a gauge. Those reports are frozen at whatever precision the scanner happened to have the day they ran. A companion capability — a one-time, per-tenant historical self-heal backfill — fixes that.
The backfill drags completed reports back through the same self-heal pipeline and — this is the important part — persists revised audit data without overwriting the original findings. The revision lives in a separate namespace, run.selfheal["historical_backfill"]; the original findings list is left untouched. You can always see both what the scanner originally said and what self-heal revised it to. It is an auditable overlay, not a mutation.
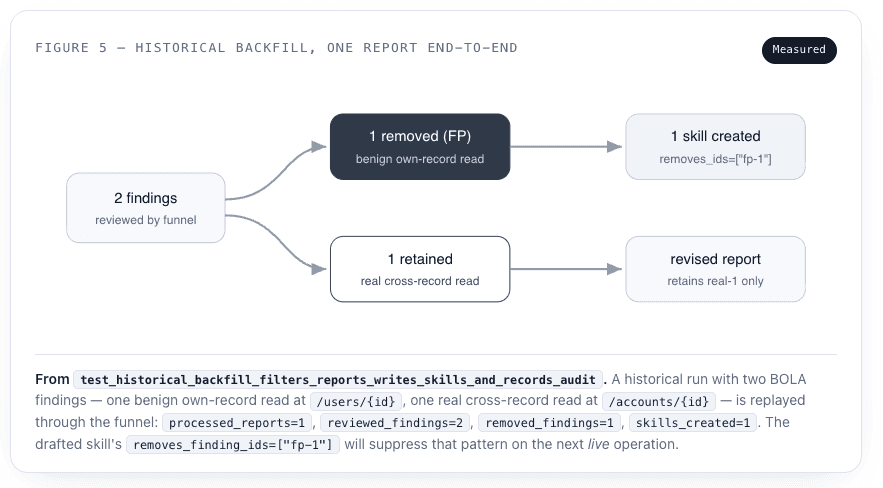
Two engineering decisions in the backfill are worth surfacing because they’re the difference between a feature and a liability at scale. Failure isolation: each report is wrapped in its own try/except, failures are recorded per-report, and the job finishes as completed_with_errors rather than aborting — one poisoned report in the middle of a 500-report backlog can’t take the rest down with it. Atomic writes: every state file is written via tempfile.mkstemp + Path.replace, so a crash mid-write leaves the previous good file intact, never a half-written blob of JSON.
And the backfill deliberately uses the single-pass healer, not the recursive engine. Bulk cleanup across a backlog should be predictable and bounded, not recursively deepening on each stale report. But it shares the same funnel, gauge, skill store, and SKILL.md format — so a lesson learned while cleaning the backlog is immediately available to suppress a false positive on the next live operation. The past and the future feed the same loop.
11Honest scope — what this cut does not do
Good engineering writing says what it didn’t build. This is the trimmed first cut of the RSI brief, and the docstrings are explicit about the boundary. Deferred for later: Tier-2 retrieval directives and Tier-3 code patches (the enum values exist for fidelity but aren’t implemented), fingerprint-scoped matching (needs embeddings, and is off in the upstream ares too), R4 multi-context replay, the second approval queue (Queue B), and the fleet-wide EWMA gauge prior.
What is real, shipped, and tested: the recursion, the meta-learning, the compounding across cycles, the convergence and termination guarantees, the honest gauge, and the full auditability of every meta-level decision in the cycle trace. The heavier machinery-tier work is staged — but the core idea is load-bearing today.
The takeaway. The interesting idea was never “we remove false positives” — we already could. It’s that the healing process is now a first-class object the system can inspect and rewrite, and because the rewrites accumulate in a fingerprinted config, the loop is guaranteed to either converge, hit a depth bound, or detect that it’s spinning. No infinite recursion, no silent churn. Skills compound across cycles, the gauge moves honestly — including against the agent — and every decision is auditable. That is the difference between self-healing and recursive self-healing.
About the data in this post
Every figure marked Measured — Figures 3, 4, and 5, plus all stat-card numbers — comes directly from Predator’s test suite. Figures 1 and 2 are labeled Schematic: they illustrate mechanisms verified by the named tests rather than reporting aggregate run statistics.
Implementation lives in predator/selfheal/ — rsi.py, machinery.py, meta_learner.py, funnel.py, gauge.py, operation_review.py, skill_files.py, constants.py — with coverage in tests/test_recursive_selfheal.py and tests/test_selfheal_backfill.py.